

深度学习优化策略---优化器的学习率调节
目录
深度卷积神经网络(CNN tricks)调参技巧(一)学习率调节
理解深度学习中的学习率及多种选择策略
1cycle策略:实践中的学习率设定应该是先增再降
The 1cycle policy
机器学习算法如何调参?这里有一份神经网络学习速率设置指南
『A DISCIPLINED APPROACH TO NEURAL NETWORK HYPER-PARAMETERS: PART 1』论文笔记
【调参】Cyclic Learning Rates和One Cycle Policy-Keras
tensorflow中常用学习率更新策略
分段常数衰减 : tf中定义了tf.train.piecewise_constant 函数,实现了学习率的分段常数衰减功能
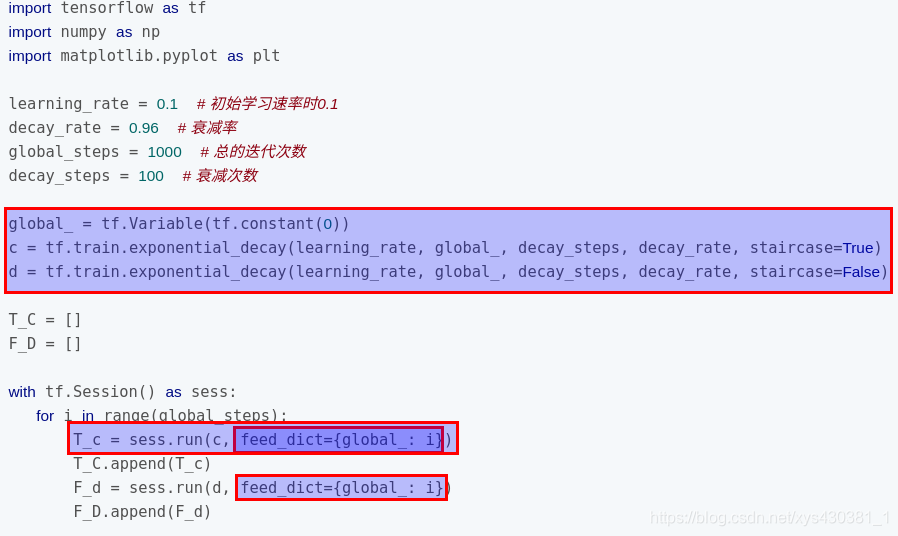
指数衰减: tf中实现指数衰减的函数是 tf.train.exponential_decay()。
自然指数衰减: tf中实现自然指数衰减的函数是 tf.train.natural_exp_decay()
多项式衰减: tf中实现多项式衰减的函数是 tf.train.polynomial_decay()
余弦衰减: tf中的实现函数是:tf.train.cosine_decay()
https://github.com/ildoonet/pytorch-gradual-warmup-lr
训练初期由于离目标较远,一般需要选择大的学习率,但是使用过大的学习率容易导致不稳定性。所以可以做一个学习率热身阶段——在开始的时候先使用一个较小的学习率,然后当训练过程稳定的时候再把学习率调回去。
比如说在热身阶段,将学习率从0调到初始学习率。举个例子,如果我们准备用m个batches来热身,准备的初始学习率是 η ,然后在每个batch
i
,
1
≤
i
≤
m
i, 1 \leq i \leq m
i,1≤i≤m ,将每次的学习率设为
i
η
/
m
i \eta / m
iη/m
论文:《Cyclical Learning Rates for Training Neural Networks》
如何找到最优学习率
代码地址:
fastai实现:https://github.com/sgugger/Deep-Learning/blob/master/Cyclical LR and momentums.ipynb
adam的实现:https://github.com/mpyrozhok/adamwr
keras实现:https://github.com/bckenstler/CLR
pytorch实现:https://github.com/anandsaha/pytorch.cyclic.learning.rate/blob/master/cls.py
如下图所示,CLR需要把握几个基本概念:
base_lr : 下界学习率。
max_lr : 上界学习率。
cycle: 学习率从下界学习率(base_lr)到上界学习率(max_lr)再到下界学习率(base_lr),所经历的迭代次数iterations。
stepsize: cycle迭代次数的一半。
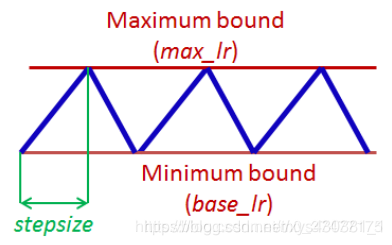
以下内容节选自https://github.com/bckenstler/CLR
The author points out that the best accuracies are typically attained by ending with the base learning rate. Therefore it’s recommended to make sure your training finishes at the end of the cycle.
在原文中,提供了三种周期学习率的方法,用的较多的是triangular策略。
1、triangular
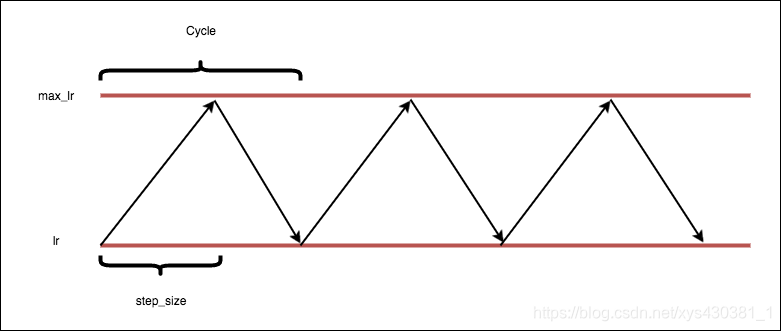
基本算法
2、triangular2
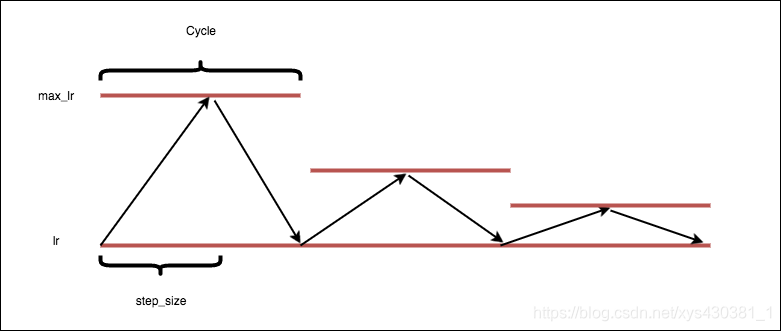
This method is a triangular cycle that decreases the cycle amplitude by half after each period, while keeping the base lr constant. This is an example of scaling on cycle number.
Basic algorithm:
3、exp_range
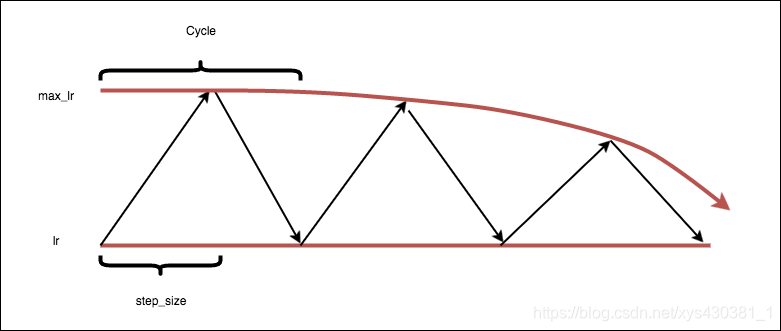
This method is a triangular cycle that scales the cycle amplitude by a factor gamma(iterations), while keeping the base lr constant.** This is an example of scaling on iteration.
Basic algorithm:
cycle = np.floor(1+iterations/(2step_size))
x = np.abs(iterations/step_size - 2cycle + 1)
lr= base_lr + (max_lr-base_lr)np.maximum(0, (1-x))gamma(iterations)
4、One Cycle Policy and Super-Convergence
源码:https://github.com/nachiket273/One_Cycle_Policy/blob/master/OneCycle.py
pytorch应用1circle:https://github.com/nachiket273/One_Cycle_Policy/blob/master/CLR.ipynb
keras实现:https://github.com/titu1994/keras-one-cycle/blob/master/clr.py
在 2017 年的近期工作中<Super-Convergence: Very Fast Training of Neural
Networks Using Large Learning Rates>,LR Range test 和 CLR 的作者将自己的想法推向了极致,其中循环学习率策略仅包含 1 个周期(一个cycle可以有多个epoch),因此称作「一周期」策略。
This is a special case of Cyclic Learning Rates, where we have only 1 cycle. After the completion of 1 cycle, the learning rate will decrease rapidly to 100th its initial lowest value。
在keras的实现代码中,可以看出,1个cycle是可以有多个epoch的。
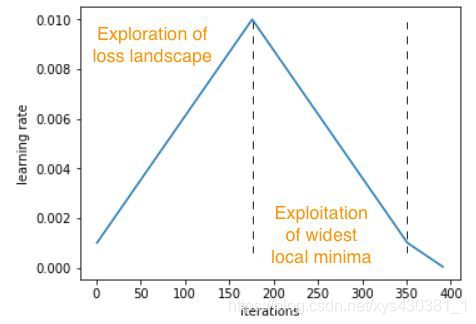
在一周期策略中,最大学习率被设置为 LR Range test 中可以找到的最高值,最小学习率比最大学习率小几个数量级。
- 先使用LR range test中的方法,找到最大的学习速率max_lr。
- 使用最大学习速度的1/5或1/10作为较低的学习速度。
- 从较低的学习率到较高的学习率,然后再回到较低的学习率。我们选择这个周期长度略小于要训练的周期总数。
- 在最后的迭代中,我们将学习率大大低于较低的学习率值(1/10或1/100)。(整个周期(向上和向下)的长度被设置为略小于训练周期的总数,这样循环结束后有残余时间降低学习率,从而帮助模型稳定下来 )
我们可以将这种策略看作是一种探索-开发的权衡,其中周期的前半部分更有可能从某一局部最优跳到另一局部最优,从而有望在最平坦、最广泛的局部最优区域达到稳定。以较大的学习率开始循环的后半部分有助于模型更快地收敛到最优。
一周期策略本身就是一种正则化技术,因此需要对其它正则化方法进行调优才能与此策略配合使用。
- 通过这一策略,作者演示了「超收敛」,它达到相同的验证准确率只需要 1/5 的迭代。
- 标记训练数越少 ,相对于其他学习率策略的收敛效果会增加。
5、如何找到合适的学习率范围
调参】如何为神经网络选择最合适的学习率lr-LRFinder-for-Keras
源码:https://github.com/surmenok/keras_lr_finder/blob/master/keras_lr_finder/lr_finder.py
https://github.com/davidtvs/pytorch-lr-finder/blob/master/lr_finder.py
学习率衰减大家都懂的,文中给出了一种可能更有效的衰减方式,我感觉之前在看一些代码的时候学习率衰减基本是step decay,多少个epoch后就除以一个数字这样子,论文里面提到的这种Cosine lr decay好像没怎么见到过,打算下次试一试,具体做法是,假设总batch size是T(忽略学习率热身阶段),初始学习率为 \eta ,那么在每个batch t, 将学习率设为: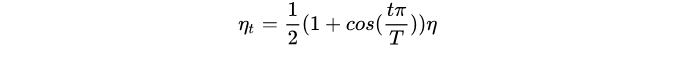
这个lr decay我看了看,貌似tensorflow里面已经实现了,可以直接拿来用
原因,在设置动态学习率时,在epoch的循环内添加了tensor,导致graph的节点越来越多。内存最终溢出。
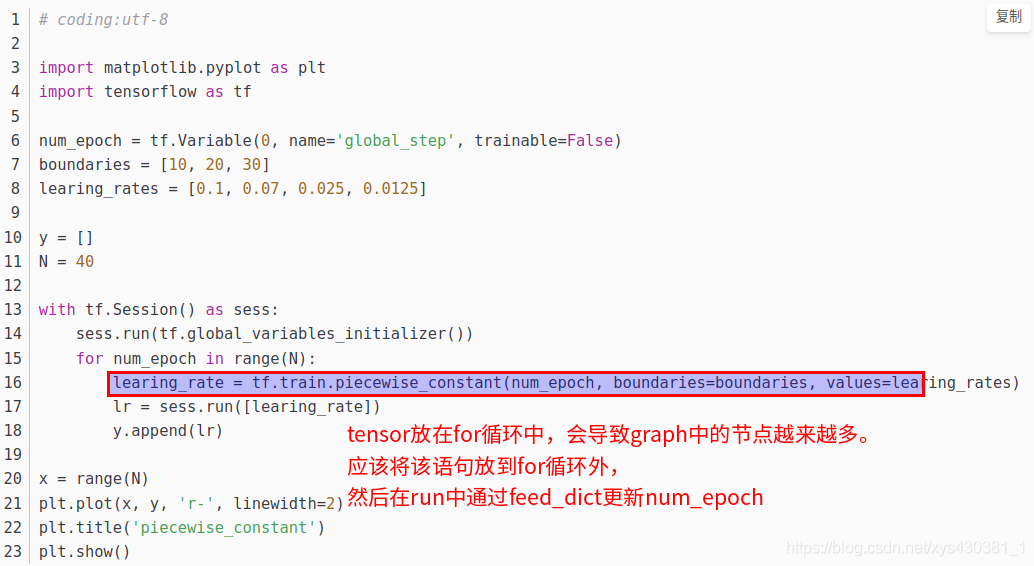
正确的方法参考:https://blog.csdn.net/u013555719/article/details/79334359
自 Adam 出现以来,深度学习优化器发生了什么变化?
LR Range test + Cyclical LR(《Cyclical Learning Rates for Training Neural Networks》)
SGDR(《SGDR: Stochastic Gradient Descent with Warm Restarts》)
SGDW? and AdamW?(《Decoupled Weight Decay Regularization in Adam》) 源码1:https://github.com/loshchil/AdamW-and-SGDW 源码2:https://github.com/mpyrozhok/adamwr
1-cycle policy and super-convergence(《Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates》) https://sgugger.github.io/the-1cycle-policy.html
Leslie N Smith. Cyclical Learning Rates for Training Neural Networks 2015
Leslie N Smith. No more pesky learning rate guessing games. arXiv preprint arXiv:1506.01186,2017.(Cyclical Learning Rates for Training Neural Networks的最新版本)
Leslie N Smith. Cyclical learning rates for training neural networks. In Applications of Computer Vision (WACV), 2017 IEEE Winter Conference on, pp. 464–472. IEEE, 2017.
Leslie N Smith and Nicholay Topin. Super-convergence: Very fast training of residual networks using large learning rates. arXiv preprint arXiv:1708.07120, 2017.
Leslie N Smith.A DISCIPLINED APPROACH TO NEURAL NETWORK HYPER-PARAMETERS: PART 1 – LEARNING RATE,BATCH SIZE, MOMENTUM, AND WEIGHT DECAY,2018

